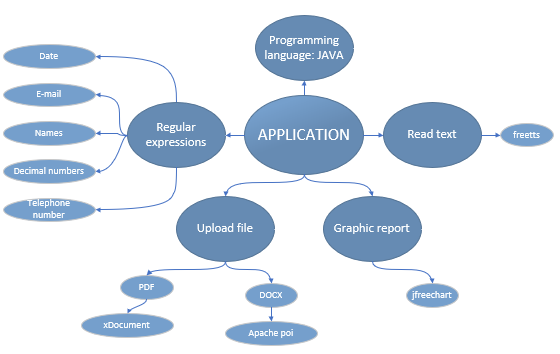
In the next entry we present how a reading comprehension application was created by using Freeling. Freeling is an open source library for linguistic analysis. It allows analyzing the structure of a sentence, assigning to each word a label that helps to recognize what kind of word it is (verb, noun, pronoun, adjective, etc.). This feature is really useful when analyzing texts.
The application has the ability to read a text and answer questions about it. The texts that are used are in English. The programming language that was used to create the application is Phyton.
In Figure 1 a scheme of the operation of the program is presented:
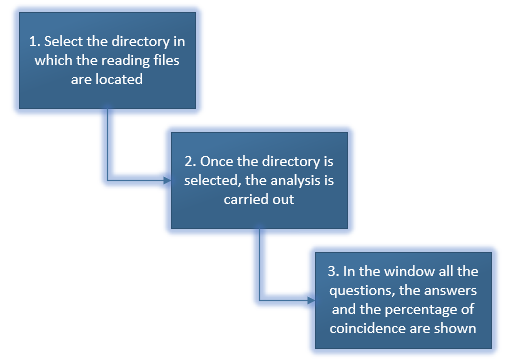
Fig. 1: Operation_reading comprehension application
1. Select the directory
You have to select the directory in which the files that you wanto to analize are. These files must be in .txt format. The directory can contain any number of files. It is important that each file has the set of questions that you want to answers will be given. These questions should be at the end of the text
2. Text analysis
The analysis is mainly based on determining which of all sentences in the text have the greatest semantic load in relation to the question that is asked. So, a percentage is given and the probable response is determined.
To carry out the code it is important to take into account the grammatical structure of both the questions and the answers:
- The questions begin with the so-called W words (what, who, where, when and why).
- The sentences have a subject, a verb and a complement.
- The question and all possible answers must be analyzed. An example is described below:
For the question: Who is Christopher Robin?
- Freeling Analysis

Freeling detects the words in the following way: W-word (Who) as WP, it means interrogative pronoun; "is" as VBZ, it means personal verb in third person; "Christopher Robin" as NP, it means proper name and finally the " ? " as Fit, it means question mark.
Una vez analizada palabra por palabra, es más fácil buscar las respuestas, la respuesta a esta pregunta debe venir nada de la siguiente manera: NP+VBZ+C (complemento). La aplicación dará mayor prioridad a las respuestas que cumplan con este criterio.
Once the application analyzed word by word, it is easier to find the answers. The answer to this question should be: NP + VBZ + C (complement). The application will give higher priority to the answers that meet this criterion.
3. Answers
Una vez analizado todo el texto, se mostrará en la ventada todas las posibles respuestas a la pregunta dada. Junto a cada respuesta se encuentra un porcentaje, entre más alto es el porcentaje la respuesta es la más probable.
Es importante mencionar, que al existir una gran cantidad de estructuras gramaticales en el idioma inglés, no siempre la respuesta con mayor porcentaje será la correcta.
Conclusión
Freeling es una herramienta de gran utilidad en el análisis de textos. Es fácil de implementar. Para crear cualquier aplicación es importante contar con las herramientas adecuadas, sin embargo es más importante aún saber como utilizarla. Para ello la funcionalidad que debe tener una aplicación debe ser clara, de esta manera se irá programando de manera lógica y racional.
La aplicación creada cumple con el objetivo principal de leer textos y dar respuestas a preguntas planteadas. Existe cierto margen de error debido a que las respuestas se basan en la coincidencia de palabras que se tiene con cada pregunta. Pero los resultados de las pruebas realizadas muestran que en general las respuestas obtenidas con mayor porcentaje son las correctas.